

基礎知識
自然言語処理(NLP)とは?仕組み・活用事例・課題をわかりやすく解説

自然言語処理とは、人間が日常的に使う日本語や英語などの言葉を、コンピュータが理解・分析・生成できるようにするための技術の総称です。検索エンジンの精度向上から、チャットボットによる問い合わせ対応、機械翻訳、文書の自動要約まで、私たちの身近なサービスの多くに自然言語処理の技術が組み込まれています。近年、ChatGPTをはじめとする大規模言語モデル(LLM)の登場により、自然言語処理は急速に注目を集めています。
本記事では、自然言語処理(NLP)の基本的な定義から、仕組み・処理ステップ・主要な技術、そしてビジネスにおける活用事例や今後の展望まで、体系的にわかりやすく解説します。
自然言語処理(NLP)とは
自然言語処理(NLP:Natural Language Processing)とは、人間が日常的に話したり書いたりする言葉をコンピュータが解析・理解・生成できるようにする技術分野であり、人工知能(AI)研究の中でも特に実用化が進んでいる領域です。
コンピュータはもともと、厳密なルールに従って記述されたプログラミング言語しか解釈できませんでした。しかし、自然言語処理の技術が発展したことで、日常会話や文書のような「人間の言葉」をそのまま入力として受け取り、意味を解釈したうえで適切な応答や処理を行えるようになっています。
以下では、自然言語処理を理解するうえで押さえておきたい基本概念を解説します。
自然言語と人工言語の違い
自然言語と人工言語の最大の違いは「あいまいさの有無」にあります。人工言語は文法が厳密に定義されており、同じコードは常に同じ動作をします。これに対し、自然言語は同じ単語や文でも文脈・話者の意図・文化的背景によって意味が変わります。たとえば「橋を渡る」という表現は、物理的な橋を歩いて渡る行為を指す場合もあれば、比喩的に困難を乗り越えることを意味する場合もあります。
そもそも自然言語とは、人間が自然に習得し日常的に使用する言語のことで、日本語・英語・中国語などがこれにあたります。一方、プログラミング言語に代表される「人工言語」は、コンピュータへの命令を記述するために人工的に設計された言語です。PythonやJavaScriptなどが代表例として挙げられます。
自然言語のあいまいさこそが、コンピュータに処理させる際の根本的な難しさです。自然言語処理の研究は、こうした人間の言語の複雑さをいかにコンピュータが扱えるかたちに変換するかという問いに、長年にわたって取り組んできました。
自然言語処理の処理の種類
NLPが扱う処理は大きく2つに分類されます。一つは「自然言語理解(NLU:Natural Language Understanding)」で、人間の言葉の意味・意図・感情をコンピュータが解釈する処理です。もう一つは「自然言語生成(NLG:Natural Language Generation)」で、データや情報をもとに人間が読める自然な文章を生成する処理です。
検索エンジンがキーワードの意図を読み取ったり、翻訳アプリが文脈に沿った訳文を生成したりできるのも、この2つの処理が組み合わさった自然言語処理技術の恩恵です。
貴社業務に特化したAIエージェントを搭載!
上場企業水準のセキュリティ環境と
活用支援を無償で提供
チャットツールなら JAPAN AI CHAT
上場企業水準のセキュリティ環境
豊富なテンプレートをご用意
自社開発のRAGで高回答精度を実現
外部連携機能をご提供

自然言語処理(NLP)が注目される理由・背景
自然言語処理(NLP)が近年急速に注目を集めている背景には、テキストデータの爆発的増加・大規模言語モデルの進化・DX推進という3つの大きな潮流があります。これらが重なり合うことで、NLPはビジネスの現場において不可欠な技術として認識されるようになっています。自然言語処理が注目される理由・背景を解説します。
- テキストデータの爆発的増加:人手での処理が限界に達している
- 大規模言語モデル(LLM)・ディープラーニングの進化:NLPの精度が飛躍的に向上
- DX推進とデジタル技術の発展:業務効率化の中核技術として需要が拡大
テキストデータの爆発的増加
SNS・メール・チャット・電子文書など、デジタルテキストデータの量は年々指数関数的に増加しており、人手での処理が現実的に不可能な水準に達しています。こうした背景が、テキストを自動処理できる自然言語処理技術への需要を押し上げています。
たとえば、企業のカスタマーサポート部門には毎日数千〜数万件の問い合わせメールが届きます。これらをすべて人間が読んで分類・回答するには膨大なコストがかかります。また、SNS上には毎秒数十万件の投稿が生成されており、マーケティング目的でこれらを手動で分析することは不可能です。自然言語処理はこうした大量のテキストデータを自動的に解析・分類・要約することで、人間の処理能力の限界を補う役割を担っています。
大規模言語モデル(LLM)・ディープラーニングの進化
ディープラーニング(深層学習)の進展と、BERTやGPTに代表される大規模言語モデル(LLM)の登場が、自然言語処理の精度を飛躍的に向上させた最大の要因です。2017年にGoogle Brainの研究者らが発表したTransformer(トランスフォーマー)アーキテクチャは、文章全体を並列処理する「注意機構(Attention)」を持ち、長文の文脈理解を可能にしました。
2018年にはBERT(Bidirectional Encoder Representations from Transformers)が登場し、文章の前後両方向から文脈を学習する双方向モデルとして自然言語処理の精度を大幅に向上させました。さらに2022年にChatGPTが公開されると、数百億パラメータを持つ大規模言語モデルが一般ユーザーにも広く普及し、NLPは「専門家の技術」から「誰もが使えるツール」へと変貌しました。
DX推進とデジタル技術の発展
企業のDX(デジタルトランスフォーメーション)推進において、自然言語処理は業務効率化の中核技術として位置づけられており、市場規模は急速に拡大しています。総務省「令和7年版 情報通信白書」によれば、日本国内のAIシステム市場は2024年に1兆3,412億円(前年比56.5%増)に達しており、2029年には4兆1,873億円への拡大が予測されています。
DX推進の文脈でNLPが特に注目される理由は、企業活動の多くが「言語」を介して行われているためです。メール・報告書・契約書・議事録・顧客の問い合わせなど、ビジネスの現場には膨大なテキストデータが存在します。これらを自動処理できるNLPは、人手不足の解消・業務スピードの向上・意思決定の高度化という観点から、DX推進の要として機能しています。
自然言語処理(NLP)の仕組み|4つの処理ステップ
自然言語処理は、テキストを段階的に分解・解析することで、コンピュータが言語の意味を理解できるようにする仕組みです。一般的に「①形態素解析→②構文解析→③意味解析→④文脈解析」という4つのステップで処理が進みます。
各ステップは独立しているわけではなく、前段階の解析結果を次の段階が引き継ぐ形で連携しています。この積み重ねによって、コンピュータは単語の羅列を「意味のある情報」として扱えるようになります。
- ①形態素解析:文を最小単位に分割し、品詞を特定する
- ②構文解析:単語間の文法的な関係を明らかにする
- ③意味解析:単語・文の意味を解釈する
- ④文脈解析:文章全体の流れや話者の意図を把握する
①形態素解析:文章を単語に分割する
形態素解析とは、文章を意味を持つ最小単位(形態素)に分割し、各単語の品詞・活用形・読みを特定する処理です。自然言語処理の最初のステップであり、後続のすべての解析の基盤となります。
たとえば、「私は学校に行く」という文を形態素解析すると、「私/は/学校/に/行く」のように分割され、それぞれに「名詞」「助詞」「名詞」「助詞」「動詞」という品詞情報が付与されます。英語と異なり、日本語は単語間にスペースがないため、この分割処理が特に重要です。形態素解析には「コーパス(大規模なテキストデータの集合体)」と機械可読辞書が活用されており、日本語では「MeCab(メカブ)」や「JUMAN++」が広く使われています。形態素解析の精度が低いと、後続の構文解析・意味解析の精度にも直接影響するため、自然言語処理技術の中でも基礎的かつ重要な工程です。
②構文解析:単語間の関係・構造を解析する
構文解析とは、形態素解析で得られた単語の列に対して、文法的な構造(係り受け関係)を明らかにする処理です。どの単語がどの単語に係るのかを解析することで、文の意味的なまとまりを把握します。
たとえば「赤い花が咲いた」という文では、「赤い」が「花」に係り、「花が」が「咲いた」に係るという構造が明らかになります。この係り受け情報があることで、コンピュータは「何が」「どうした」という述語論理を正確に把握できます。構文解析は、機械翻訳・情報抽出・質問応答システムなど、多くの自然言語処理タスクで活用されています。文の構造が正確に把握できなければ、翻訳の際に語順が崩れたり、情報抽出で誤った要素を取り出したりするリスクがあります。
③意味解析:文章全体の意味を正しく理解する
意味解析とは、単語や文が持つ意味を解釈し、文章が表す概念・関係性を理解する処理です。構文解析が「文の形」を解析するのに対し、意味解析は「文の内容」を解析します。
意味解析では、単語の多義性(同音異義語・同形異義語)の解消が重要な課題です。たとえば「橋を渡る」と「箸を渡す」は発音が似ていますが意味は全く異なります。また「彼は私の友人の先生だ」という文では、「友人の先生」が「友人が通う学校の先生」なのか「友人が師と仰ぐ人物」なのかを文脈から判断する必要があります。近年は単語をベクトル(数値の配列)として表現する「単語埋め込み(Word Embedding)」技術が発展し、意味的に近い単語同士が数値空間上でも近い位置に配置されるようになりました。これにより、コンピュータが単語の意味的な類似性を定量的に扱えるようになっています。
④文脈解析:複数文の関係性・文脈を把握する
文脈解析とは、単一の文を超えて文章全体の流れや話者の意図・感情を把握する処理であり、自然言語処理の中で最も高度な段階です。
たとえば、「昨日は疲れた。だから今日は休んだ」という2文では、「だから」という接続詞が前後の因果関係を示しています。文脈解析はこうした文間の関係性を解析し、文章全体の意味的なまとまりを理解します。また、対話システムでは「それ」「あれ」といった指示語が何を指すのかを前の発話から特定する「照応解析」も文脈解析の一部です。ChatGPTが会話の流れを記憶して文脈に沿った回答を生成できるのも、この文脈解析の精度が高いためです。自然言語理解(NLU)の観点では、文脈解析こそが人間らしい言語理解を実現する最重要ステップといえます。
自然言語処理(NLP)でできること|主な種類と機能
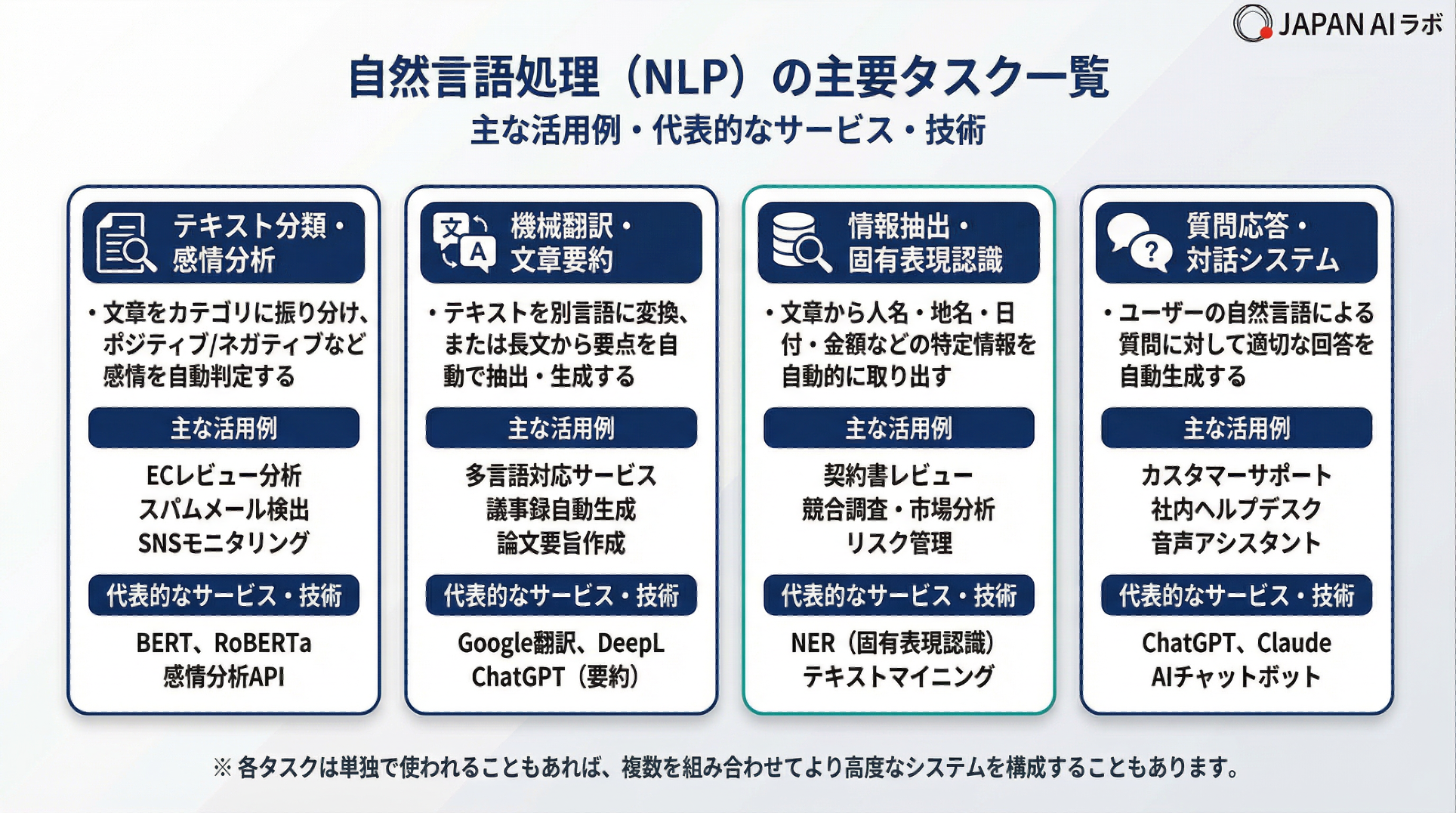
自然言語処理(NLP)が実現できる機能は、「自然言語理解(NLU)」と「自然言語生成(NLG)」の2軸に大別されます。NLUは人間の言葉の意味・意図・感情をコンピュータが解釈する処理群であり、NLGはデータや情報から人間が読める自然な文章を生成する処理群です。この2つが組み合わさることで、テキスト分類・感情分析・機械翻訳・文章生成など、言語に関わるほぼあらゆる処理が実現されています。
- 自然言語理解(NLU):言葉を「理解」する処理群
- 自然言語生成(NLG):言葉を「生成」する処理群
自然言語理解(NLU):言葉を「理解」する
自然言語理解(NLU:Natural Language Understanding)とは、人間の言葉の意味・意図・感情をコンピュータが解釈する処理の総称です。NLPの「入力側」を担う機能群であり、感情分析・テキスト分類・固有表現抽出などが代表的なタスクです。
感情分析では、テキストに含まれる感情(ポジティブ・ネガティブ・ニュートラルなど)を自動的に判定します。ECサイトのレビューコメントを「高評価」「低評価」「中立」に自動分類したり、SNS投稿から製品に対するユーザーの感情傾向を把握したりする用途に活用されています。テキスト分類は、スパムメールの自動検出やニュース記事のカテゴリ分類(政治・経済・スポーツなど)にも応用されています。固有表現抽出(NER:Named Entity Recognition)は、文章から人名・地名・日付・金額などの特定情報を自動的に取り出す処理で、法務・医療・金融分野での文書解析に広く活用されています。
自然言語生成(NLG):言葉を「生成」する
自然言語生成(NLG:Natural Language Generation)とは、データや情報をもとに人間が読める自然な文章を自動生成する処理の総称です。NLPの「出力側」を担う機能群であり、文章要約・機械翻訳・チャットボット応答・レポート自動生成などが代表的なタスクです。
文章要約は、長い文書から重要な情報を抽出して短くまとめる処理です。「抽出型要約」(元の文章から重要な文をそのまま抜き出す)と「生成型要約」(内容を理解したうえで新たな文章として生成する)の2種類があります。大規模言語モデル(LLM)の登場により生成型要約の精度が飛躍的に向上し、会議の議事録作成や論文の要旨生成などへの実用化が進んでいます。チャットボットの応答生成もNLGの代表例であり、ユーザーの問い合わせ内容を理解(NLU)したうえで、適切な回答文を生成(NLG)するという2段階の処理が組み合わさっています。
生成AIとNLPの関係についてより詳しくは、生成AIとは?従来のAIとの違いやできることなどわかりやすく解説もあわせてご参照ください。
様々な業務を自律的に遂行するAIエージェント「JAPAN AI CHAT」

貴社業務に特化したAIエージェントを搭載!
上場企業水準のセキュリティ環境と
活用支援を無償で提供
チャットツールなら JAPAN AI CHAT
上場企業水準のセキュリティ環境
豊富なテンプレートをご用意
自社開発のRAGで高回答精度を実現
外部連携機能をご提供
自然言語処理(NLP)の活用事例|身近な例
自然言語処理(NLP)は、チャットボット・音声認識・機械翻訳・テキストマイニング・検索エンジンなど、私たちが日常的に使っているサービスの多くに組み込まれている技術です。身近な例を紹介します。
- 対話型AIチャットボット
- 音声認識AI・スマートスピーカー
- 機械翻訳
- テキストマイニング・感情分析
- 検索エンジン・AI-OCR・その他
対話型AIチャットボット
自然言語処理を活用した対話型AIチャットボットは、カスタマーサポートの自動化・効率化において最も普及している応用例の一つです。ユーザーが入力した問い合わせ文を解析し、適切な回答を自動生成することで、24時間365日の対応を少人数で実現できます。
従来のFAQシステムは、ユーザーが正確なキーワードを入力しなければ目的の情報にたどり着けませんでした。これに対してNLPベースのチャットボットは、「料金はいくらですか」「費用を教えてください」のように表現が異なる問い合わせでも、同じ意図として認識して回答できます。ChatGPTをはじめとする生成AIの登場により、さらに高度な文脈理解と柔軟な応答生成が可能になっています。
AIチャットボットの特徴について、詳しくはAIチャットボットとは?特徴や利用時の注意点を解説をご参照ください。
音声認識AI・スマートスピーカー
音声認識AIは、人間の話し言葉をテキストに変換する処理に自然言語処理を活用しており、スマートスピーカーやAI議事録自動作成ツールなどに広く応用されています。SiriやAlexaなどの音声アシスタントは、音声認識でテキスト化した発話内容をNLPで解析し、意図を把握したうえで適切な応答を返しています。
音声認識とNLPの組み合わせは、ビジネスの現場でも急速に普及しています。会議の音声をリアルタイムでテキスト化し、要点をまとめた議事録を自動生成するツールは、会議後の文書作成にかかる時間を大幅に削減可能です。また、コールセンターでは通話内容を自動でテキスト化・分析することで、顧客対応の品質管理や改善点の抽出に活用されています。
AIを用いて問い合わせ対応を自動化する方法に関しては、問い合わせ対応を自動化する方法を解説もあわせてご覧ください。
>議事録作成をAIで自動化できる「JAPAN AI SPEECH」の詳細はこちら
機械翻訳
機械翻訳とは、ある言語で書かれたテキストを別の言語に自動変換する処理であり、自然言語処理の中でも最も歴史が長く、かつ実用化が進んでいるタスクの一つです。Google翻訳やDeepLなどのサービスは、Transformerベースのニューラル機械翻訳(NMT)を採用しており、文脈を考慮した高精度な翻訳を実現しています。
従来のルールベース翻訳や統計的機械翻訳と比較して、ニューラル機械翻訳は文章全体の文脈を考慮したうえで翻訳を行うため、自然な訳文を生成できます。たとえば、「I saw her duck」という英文は「彼女がかがむのを見た」とも「彼女のアヒルを見た」とも訳せますが、前後の文脈があれば正確な意味を判断できます。
AI翻訳をビジネスで活用する具体的な方法については、ChatGPTを使った翻訳の方法と活用のメリットを解説もご参照ください。
テキストマイニング・感情分析
テキストマイニングとは、大量のテキストデータから有用な知識・パターンを自動的に発見する技術であり、感情分析はその代表的な応用例です。SNS投稿・レビューコメント・アンケート回答などの大量のテキストデータを自動解析することで、製品・サービスに対する顧客の感情傾向や潜在的なニーズを把握できます。
たとえば、新製品発売後にSNS上の投稿を感情分析にかけることで、ポジティブな反応とネガティブな反応の比率をリアルタイムで把握し、マーケティング施策の改善に活かすことができます。また、競合他社の製品に関する口コミを自動収集・分析することで、市場における自社製品の強みと弱みを客観的に把握する競合分析にも活用されています。テキストマイニングは、企業の競合調査・市場分析・リスク管理など、ビジネスインテリジェンスの分野での活用が広がっています。
検索エンジン・AI-OCR・その他
自然言語処理は、検索エンジン・AI-OCR(光学文字認識)・予測変換など、私たちが日常的に使っているさまざまなサービスの根幹を支えています。Googleの検索エンジンは、ユーザーが入力したキーワードの意図を自然言語処理で解析し、単なるキーワードマッチングではなく「検索者が本当に知りたいこと」に合致したページを上位表示します。
AI-OCRは、紙の文書や手書き文字を画像として読み取り、テキストデータに変換する技術です。従来のOCRが印刷文字の認識に特化していたのに対し、AI-OCRは自然言語処理と組み合わせることで、崩れた手書き文字や複雑なレイアウトの文書も高精度で認識できます。また、スマートフォンのキーボードに搭載された予測変換機能も、過去の入力履歴と言語モデルを組み合わせた自然言語処理の応用例です。
AIを活用した業務効率化の具体的な事例については、AIによる業務効率化の事例と活用効果を解説もご参照ください。
自然言語処理(NLP)の課題・難しさ
自然言語処理(NLP)は目覚ましい進化を遂げている一方で、言語の曖昧性・一般常識の学習・言語による精度差など、本質的な課題も依然として残っています。技術の恩恵を最大限に活かすためには、これらの課題を正確に理解したうえで活用することが重要です。
- 自然言語の曖昧性・多義性:同じ言葉でも文脈によって意味が変わる
- 一般常識・世界知識の学習の難しさ:人間が暗黙的に持つ知識の習得が困難
- 言語による精度差・バイアスの問題:英語以外の言語での精度が相対的に低い
自然言語の曖昧性・多義性
自然言語処理が技術的に難しい最大の理由の一つが、人間の言語が持つ曖昧性・多義性にあります。同じ単語や文でも文脈によって意味が変わるため、コンピュータが正確に解釈するには高度な文脈理解が必要です。
たとえば、「橋」と「箸」は発音が同じですが意味は全く異なります。また「彼は私の友人の先生だ」という文は、「友人が通う学校の先生」なのか「友人が師と仰ぐ人物」なのかが文脈なしには判断できません。さらに「大きい問題」と「大きい荷物」では「大きい」の意味合いが異なるように、単語の意味は組み合わせによっても変化します。こうした曖昧性の解消には、文章全体の文脈・話者の背景・社会的な常識など、テキスト外の情報も考慮する必要があり、現在のNLP技術でも完全な解決には至っていません。
一般常識・世界知識の学習の難しさ
人間が暗黙的に持つ一般常識や世界知識をコンピュータに学習させることは、自然言語処理における根本的な難題の一つです。人間は「火は熱い」「水は下に流れる」「夜は暗い」といった常識を意識せずに言語理解に活用していますが、コンピュータはこれらを明示的に学習しなければ理解できません。
たとえば、「彼はナイフで肉を切った。それは鋭かった」という文では、「それ」がナイフを指すことを人間は即座に理解できます。しかしコンピュータがこれを正確に解釈するには、「ナイフは鋭い道具である」という常識的な知識が必要です。大規模言語モデル(LLM)は膨大なテキストデータから多くの常識的知識を学習していますが、学習データに含まれない知識や、文化・地域によって異なる常識については依然として誤りが生じやすい状況です。
産業技術総合研究所(AIST)の解説記事によれば、言語モデルの出力をより正確にする技術は進歩を続けているものの、間違いを完全にゼロにするのは難しく、重要な情報の確認には人間による検証が不可欠とされています。
言語による精度差・バイアスの問題
現在の自然言語処理モデルは、英語を中心とした学習データで構築されているため、日本語を含む非英語言語での処理精度は英語と比較して相対的に低い傾向があります。また、学習データに含まれる社会的偏見がモデルの出力に反映される「バイアス」の問題も重要な課題です。
言語による精度差の背景には、学習データの量的な偏りがあります。インターネット上のテキストデータは英語が圧倒的に多く、日本語・アラビア語・スワヒリ語などの言語は相対的にデータ量が少ないため、モデルの学習が不十分になりやすい状況です。バイアスの問題については、性別・人種・文化に関するステレオタイプが学習データに含まれている場合、モデルがそれを再現・強化してしまうリスクがあります。これらの課題に対応するため、多言語対応モデルの開発や、バイアス検出・除去のための研究が世界各地で進められています。
自然言語処理(NLP)の最新動向と将来の展望
自然言語処理(NLP)の最新動向として最も注目されているのが、Transformer・BERT・GPTに代表されるアーキテクチャの進化と、それを基盤とした大規模言語モデル(LLM)・生成AIの急速な普及です。さらに今後は、テキスト・画像・音声を統合するマルチモーダルAIとの融合や、個人に最適化されたパーソナルAIの実現が期待されています。
自然言語処理(NLP)の最新動向と将来の展望について解説します。
- トランスフォーマー・BERT・GPTの登場と進化
- 大規模言語モデル(LLM)と生成AIの台頭
- 今後の展望:マルチモーダル化・パーソナル化
トランスフォーマー・BERT・GPTの登場と進化
2017年にGoogle Brainの研究者らが発表したTransformer(トランスフォーマー)は、自然言語処理の歴史における最大の転換点となったアーキテクチャです。それ以前の主流だったRNN(再帰型ニューラルネットワーク)が文章を逐次処理していたのに対し、Transformerは「注意機構(Attention Mechanism)」により文章全体を並列処理できるため、長文の文脈理解と学習速度が飛躍的に向上しました。
2018年にはGoogleがBERT(Bidirectional Encoder Representations from Transformers)を発表しました。BERTは文章の前後両方向から文脈を学習する双方向モデルであり、質問応答・感情分析・固有表現認識など多くのNLPタスクで当時の最高精度を更新しました。同年にはOpenAIがGPT(Generative Pre-trained Transformer)を発表し、大規模テキストデータによる事前学習と特定タスクへのファインチューニングという手法が確立されました。これらの技術的蓄積が、後のChatGPTや大規模言語モデルの基盤となっています。
大規模言語モデル(LLM)と生成AIの台頭
大規模言語モデル(LLM:Large Language Model)とは、Transformerアーキテクチャをベースに、数百億〜数千億規模のパラメータと膨大なテキストデータで学習した言語モデルのことです。2022年にChatGPTが公開されると、LLMは一般ユーザーにも広く普及し、自然言語処理は「専門家の技術」から「誰もが使えるツール」へと変貌しました。
LLMと生成AIの関係を整理すると、生成AIはNLPを活用して新しいテキスト・画像・音声などを生成することに特化した技術であり、ChatGPT・Gemini・Claudeなどはその代表例です。LLMの特徴は、特定のタスクに特化せず、翻訳・要約・質問応答・文章生成・プログラミング支援など多様なタスクを一つのモデルで処理できる汎用性にあります。総務省「令和7年版 情報通信白書」によれば、世界の生成AI市場は2024年の361億ドルから2030年には3,561億ドルへと拡大すると予測されており、LLMを中心とした自然言語処理技術の社会実装は今後さらに加速する見通しです。
自然言語処理の今後の展望(マルチモーダル・パーソナル化)
自然言語処理の今後の展望として最も注目されているのが、テキスト・画像・音声・動画などを統合的に処理する「マルチモーダルAI」との融合と、個人に最適化された「パーソナルAI」の実現です。
マルチモーダルAIは、従来のNLPがテキストのみを対象としていたのに対し、複数の情報形式を組み合わせて処理することで、より豊かな文脈理解を実現します。画像を見て内容を説明したり、グラフを読み取って分析コメントを生成したりする能力は、すでにChatGPTやGeminiなどの最新モデルで実用化されています。
パーソナル化の観点では、ユーザーの過去の行動・好み・専門知識レベルを記憶し、個人に最適化された応答を生成するAIの開発が進んでいます。また、AIエージェント(設定された目標に対して自律的にタスクを実行するシステム)との組み合わせにより、自然言語による指示だけで複雑な業務フローを自動実行する仕組みも急速に発展しています。
AIエージェントの詳細については、AIエージェントとは?生成AIとの違いから特徴や事例を徹底解説をご参照ください。
自然言語処理(NLP)に関してよくある質問
自然言語処理(NLP)について、よくある疑問にお答えします。
- Q. 自然言語処理(NLP)と生成AIの違いは何ですか?
- Q. 自然言語処理(NLP)を業務に活用するにはどうすればよいですか?
- Q. 自然言語処理(NLP)を学ぶにはどこから始めればよいですか?
Q. 自然言語処理(NLP)と生成AIの違いは何ですか?
自然言語処理(NLP)は言語を「理解・解析・生成」する技術の総称であり、生成AIはNLPを活用して新しいテキストや画像などのコンテンツを生成することに特化した技術です。両者は包含関係にあり、生成AIはNLPの応用の一つと位置づけられます。
具体的には、ChatGPTはNLPの技術(特に大規模言語モデル)を活用して構築された生成AIサービスです。NLPがなければChatGPTは存在できませんが、NLPはChatGPT以外にも検索エンジン・機械翻訳・感情分析など多様な用途に活用されています。「NLP=ChatGPT」ではなく、「ChatGPTはNLPを活用した生成AIの一例」という理解が正確です。
ChatGPTとは何かさらに詳しく知りたい方はこちらの記事をご覧ください。
Q. 自然言語処理(NLP)を業務に活用するにはどうすればよいですか?
自然言語処理を業務に活用する最短ルートは、目的を明確化したうえでクラウドサービスのAPIを活用することです。自社でモデルを開発する必要はなく、既存のサービスを組み合わせることで多くの業務課題を解決できます。
具体的には、チャットボット導入であればChatGPT API・Google Dialogflow、テキストマイニングであればGoogle Cloud Natural Language API・Azure AI Language、文章要約・翻訳であればDeepL API・ChatGPT APIなどが活用できます。まずは「どの業務課題をNLPで解決したいか」を明確にし、小規模なPoC(概念実証)から始めることが推奨されます。
ChatGPTのビジネス活用事例については、【業務別】ビジネスにおけるChatGPTの活用事例10選もあわせてご参照ください。
Q. 自然言語処理(NLP)を学ぶにはどこから始めればよいですか?
自然言語処理を学ぶ入門として最適なのは、PythonとNLPライブラリ(NLTK・spaCy・Transformers)の組み合わせです。Pythonは機械学習・NLP分野で最も広く使われているプログラミング言語であり、豊富な学習リソースが揃っています。
学習の進め方としては、①Pythonの基礎文法の習得→②形態素解析・テキスト前処理の実践(MeCab・spaCy)→③機械学習の基礎(scikit-learn)→④ディープラーニング・Transformerの理解(PyTorch・Hugging Face Transformers)という順序が一般的です。書籍では「ゼロから作るDeep Learning 2(自然言語処理編)」(斎藤康毅著)が日本語NLPの入門書として定評があります。また、Hugging Faceが提供する無料のオンラインコース「NLP Course」は、最新のTransformerベースのモデルを実践的に学べる優れたリソースです。
自然言語処理技術を活用したAIソリューションの利用なら、「JAPAN AI」
自然言語処理(NLP)は、人間の言葉をコンピュータが理解・分析・生成できるようにする技術であり、現代のAIサービスの根幹を支える基盤技術です。本記事で解説した内容を以下に整理します。
- 自然言語処理(NLP)とは:人間の言語をコンピュータが扱えるようにする技術の総称。自然言語理解(NLU)と自然言語生成(NLG)の2軸で構成される
- 注目される理由:テキストデータの爆発的増加・LLMの進化・DX推進の3つの潮流が重なり合っている
- 4つの処理ステップ:形態素解析→構文解析→意味解析→文脈解析の順で言語を解析する
- 主な活用事例:チャットボット・音声認識・機械翻訳・テキストマイニング・検索エンジンなど身近なサービスに広く活用
- 課題:言語の曖昧性・一般常識の学習困難・言語による精度差・バイアスへの対処が必要
- 最新動向と展望:Transformer・LLM・生成AIの進化に加え、マルチモーダルAIとの融合・パーソナル化が次の焦点
自然言語処理技術は、適切に活用することで業務効率化・顧客体験の向上・意思決定の高度化など、多くのビジネス価値をもたらします。技術の特性と課題を正しく理解したうえで、自社の業務課題に合った形での導入を検討しましょう。
自然言語処理技術を活用したAIソリューションを業務に活用したい場合は、最新のLLMモデルを利用できる「JAPAN AI」がおすすめです。自社独自の環境で、学習されないセキュアな環境を構築できます。導入時の課題整理や伴走支援もするので、お気軽に資料をダウンロードしてみてください。
様々な業務を自律的に遂行するAIエージェント「JAPAN AI CHAT」
貴社業務に特化したAIエージェントを搭載!
上場企業水準のセキュリティ環境と
活用支援を無償で提供
チャットツールなら JAPAN AI CHAT
上場企業水準のセキュリティ環境
豊富なテンプレートをご用意
自社開発のRAGで高回答精度を実現
外部連携機能をご提供
この記事をシェアする



AIを活用した業務工数の削減 個社向けの開発対応が可能
事業に沿った自社専用AIを搭載できる「JAPAN AI CHAT」で業務効率化!
資料では「JAPAN AI CHAT」の特徴や他にはない機能をご紹介しています。具体的なAIの活用事例や各種業務での利用シーンなどもまとめて掲載。
あわせて読みたい記事









