

基礎知識
ハルシネーションとは?発生の原因・種類・事例・生成AIにおける対策を徹底解説

生成AI(人工知能)の業務活用が急速に広がるなか、「AIが事実と異なる情報を自信満々に答えてしまう」という現象が、企業の現場で深刻な問題として浮上しています。この現象がハルシネーションです。
生成AIを企業で利用する際に、ハルシネーションがネックになっていることで導入に踏み切れない企業も多いのではないでしょうか。ハルシネーションへの正しい理解と対策は、もはや一部のIT担当者だけの問題ではありません。
本記事では、ハルシネーションとは何か、その意味・語源から、発生する原因・種類・具体的な事例、企業が直面するリスク、そして今日から実践できる対策方法までわかりやすく解説します。
【2026年】法人向け生成AIサービスおすすめ15選を比較!タイプ別にご紹介
ハルシネーションとは
ハルシネーションとは、人工知能(AI)が事実に基づかない情報を、あたかも正確であるかのように生成してしまう現象のことです。まるでAIが幻覚を見ているかのように、もっともらしい嘘(事実とは異なる内容)を出力することから、この名称が使われています。
ChatGPTやGeminiのような会話型AIサービスでは、ユーザーの質問に対してAIが回答しますが、どのようなデータに基づき回答されたのかがわからない場合、それが真実なのか誤りなのかをユーザーが判断することは困難です。ハルシネーションは、生成AIの信頼性に関わる根本的な問題であり、この問題を解消するために世界中で研究が進められています。
ハルシネーションの意味・語源
ハルシネーションという名称は、英語で幻覚・幻影を意味する「hallucination」に由来します。もともとは医学・心理学の用語で、実際には存在しないものを知覚してしまう症状を指します。AIの文脈では、AIが存在しない事実・人物・文献などを、まるで実在するかのように出力してしまう特性が「幻覚」と重ねられ、ハルシネーションと呼ばれるようになりました。
なお、日本語では「AI幻覚」とも呼ばれることがあります。
ハルシネーションの具体例
ハルシネーションがどのような形で現れるか、わかりやすい具体例を紹介します。AIを利用したことがある方なら心当たりがあるでしょう。
- 存在しない論文・研究を引用する(著者名・タイトル・出版年まで正確な書式で出力する)
- 実在しない人物の経歴・受賞歴・発言を生成する
- 架空の法律条文・判例を、実在するかのように提示する
- 実在する企業・製品について、事実と異なるスペックや価格を回答する
- 歴史的な出来事の日付・場所・登場人物を誤って生成する
これらの出力は、文章の流れや語調が自然で一見すると正確な情報に見えるため、専門知識のない読者が誤りに気づきにくいという点が特に問題です。もっともらしい誤情報を生成するという特性が、ハルシネーションを単なる誤字・脱字とは異なる深刻なリスクにしています。
様々な業務を自律的に遂行するAIエージェント「JAPAN AI AGENT」

日本企業のための
最も実用的なAIエージェントへ!
AIが企業の様々な職種の
方々が
普段行っている
タスクを自律的に実行
JAPAN AI AGENT
実用性の高いAIエージェンを提供
無料の伴走サポート
高いカスタマイズ性
目標設定をだけで自律的にAIが各タスクを実行

ハルシネーションの種類
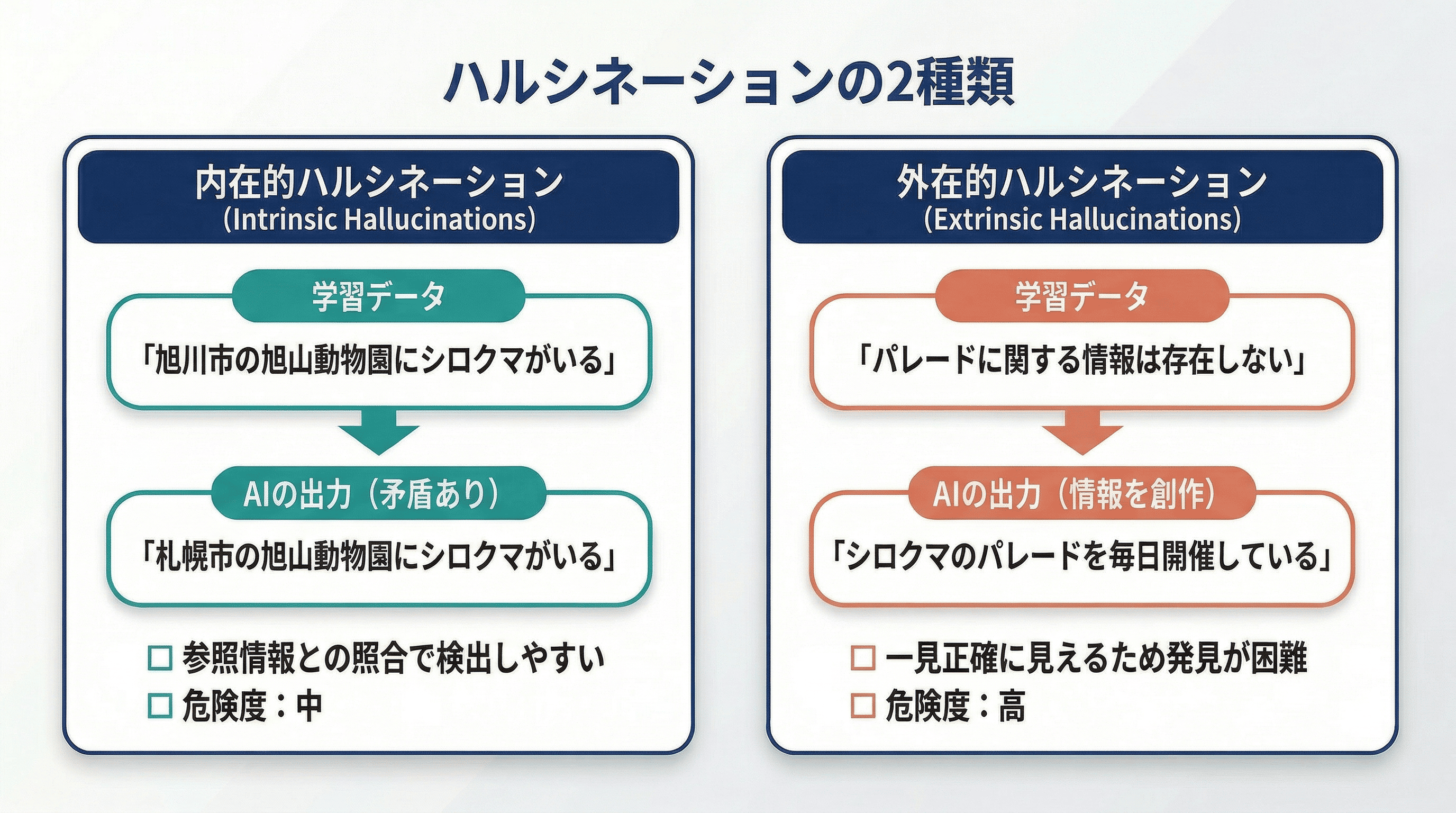
ハルシネーションは、発生のメカニズムによって内在的ハルシネーションと外在的ハルシネーションの大きく2種類に分類されます。それぞれの特徴を理解することが、適切な対策を講じるうえで重要です。ハルシネーションの種類の違いを解説します。
| 種類 | 概要 | 特徴 |
| 内在的ハルシネーション(Intrinsic Hallucinations) | 学習データに含まれる情報と矛盾する内容を出力する | 参照情報との照合で検出しやすい |
| 外在的ハルシネーション(Extrinsic Hallucinations) | 学習データに存在しない情報を新たに「創作」して出力する | 一見正確に見えるため発見が難しく、危険度が高い |
内在的ハルシネーション(Intrinsic Hallucinations)
内在的ハルシネーションとは、学習データに含まれる情報と矛盾する内容を出力してしまうタイプのハルシネーションです。AIが学習した事実と異なる情報を生成するケースが該当します。
わかりやすい例を挙げると、学習データに「旭川市の旭山動物園では、シロクマを飼育しています」という情報が含まれているにもかかわらず、AIが「札幌市の旭山動物園では、シロクマを飼育しています」と回答するようなケースです。学習データ内の事実と矛盾する出力が生成されています。
内在的ハルシネーションは、参照情報との照合によって比較的検出しやすいという特徴があります。ただし、参照情報を持たない一般ユーザーにとっては、誤りに気づくことが難しい場合もあります。
外在的ハルシネーション(Extrinsic Hallucinations)
外在的ハルシネーションとは、学習データに存在しない情報を新たに「創作」して出力してしまうタイプのハルシネーションです。存在しない論文・人物・出来事を生成するケースが該当し、2種類のなかでより危険度が高いとされています。
たとえば、「旭川市の旭山動物園では、シロクマの親子が園内を散歩するパレードを行っています」という回答を出力したケースが外在的ハルシネーションにあたります。学習データにはパレードについての情報が存在しないため、事実かどうかの検証ができない情報が新たに生成されています。
外在的ハルシネーションが特に問題なのは、出力内容が一見正確に見えるため発見が難しい点です。存在しない論文の著者名・出版年・タイトルを正確な書式で出力したり、架空の統計データを具体的な数値とともに提示したりするため、専門知識を持たない担当者が見落としやすく、企業リスクの観点から特に注意が必要です。
ハルシネーションが発生する原因
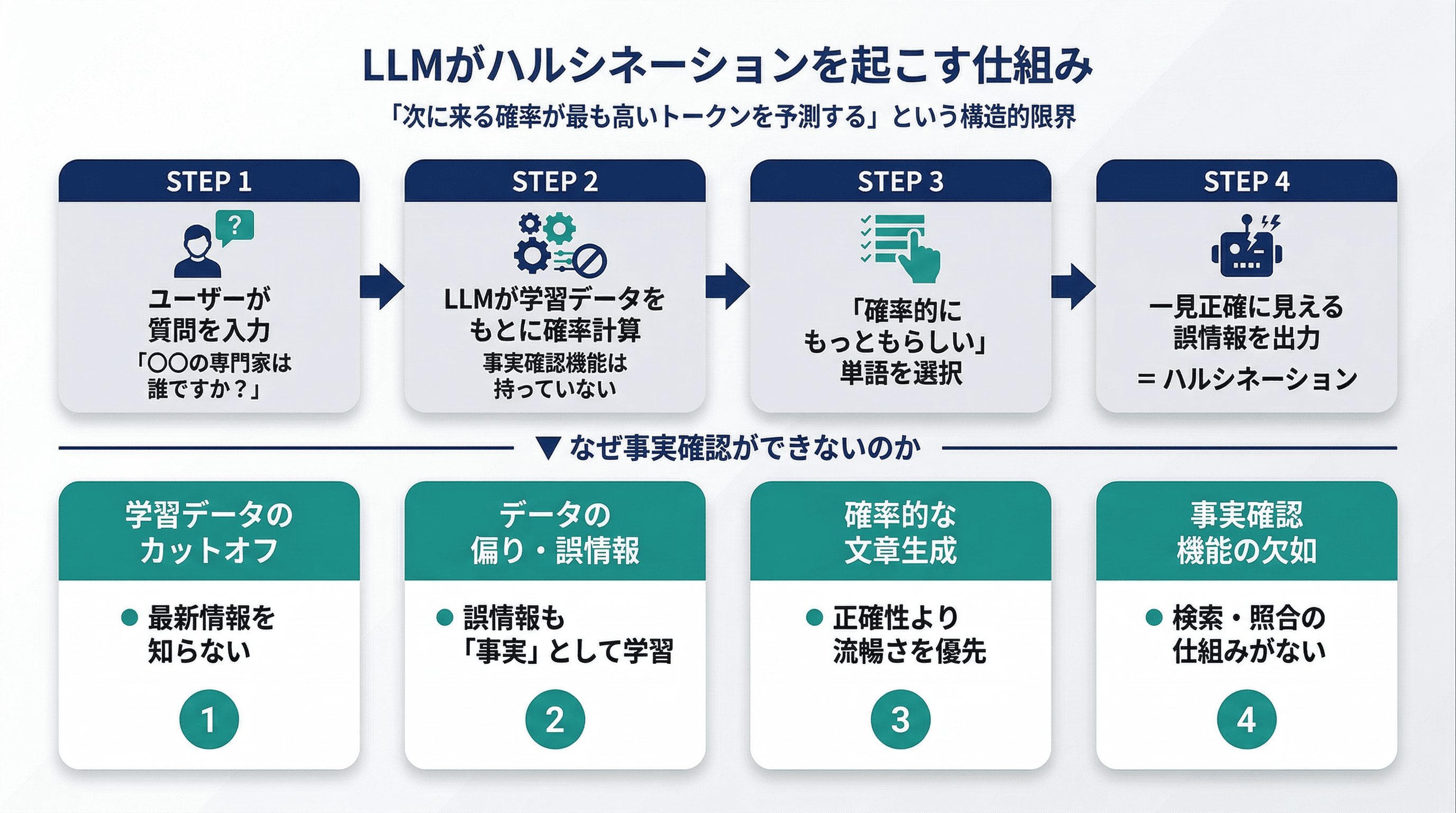
ハルシネーションが起こる原因は、大きく「学習データの問題」「AIモデルの構造的限界」「使用環境の問題」の3軸に整理できます。
重要なのは、AIが「意図的に嘘をついている」わけではないという点です。生成AIの中核にある大規模言語モデル(LLM)は、膨大なテキストデータをもとに「次に来る確率が最も高い単語・フレーズ」を予測して文章を生成します。つまり、「正しい情報を検索して答える」のではなく、「統計的にもっともらしい文章を生成する」という仕組みで動いています。この確率的な生成プロセスの結果として、事実と異なる情報が出力されることがあります。これがハルシネーションの本質です。
「なぜAIは嘘をつくのか?」という疑問に答えるために、ハルシネーションが発生する主な原因を解説します。それぞれを理解することで、どの段階でどのような対策が有効かを判断できるようになります。
学習データの偏り・不足
生成AIのハルシネーションの最も根本的な原因のひとつが、学習データの偏りや不足です。LLMは学習データに含まれる情報の範囲内でしか正確な回答を生成できません。特定の分野・言語・時代に偏ったデータで学習されたモデルは、その偏りを反映した出力を行います。
たとえば、日本語の専門的な法律・医療情報が学習データに少ない場合、モデルは英語圏の情報をもとに「それらしい」日本語の回答を生成しようとします。その結果、日本の法律体系とは異なる内容が、あたかも正確な情報として出力されることがあります。また、学習データに誤情報が含まれていた場合、その誤情報がモデルに「事実」として学習されてしまうリスクもあります。
さらに、学習データには「知識のカットオフ」と呼ばれる時点制限があります。カットオフ以降に発生した出来事や更新された情報をモデルは知らないため、最新の法改正・新製品の仕様・直近の統計データなどを問い合わせた場合、ハルシネーションが起こってしまいます。
【関連記事】
LLM(大規模言語モデル)とは?生成AIやChatGPTとの違い、仕組み・活用例まで
プロンプト(指示)の曖昧さ
ユーザーが入力する指示文(プロンプト)が曖昧・不明確な場合も、ハルシネーションの発生リスクが高まります。モデルは曖昧な指示に対して「意図を推測」しながら回答を生成しますが、その推測が外れた場合、事実と異なる内容が出力されます。
たとえば、「最近の市場動向を教えて」という曖昧な質問より、「2025年の国内生成AI市場規模について、公的機関の統計データをもとに教えてください」という具体的な質問のほうが、ハルシネーションの発生を抑えやすくなります。プロンプトを明確にすることは、ハルシネーション対策として最もコストのかからない手法のひとつです。
【関連記事】
ChatGPTで効果の高いプロンプト作成の際を行う際に意識すべき9つのコツと活用例
AIモデル自体の構造的限界
LLMは「次に来る確率が高いトークンを予測する」仕組みであり、事実確認機能を本質的に持っていません。これがハルシネーションの構造的な原因です。
LLMは文章を生成する際、「この文脈でこの単語が来る確率が最も高い」という判断を繰り返します。この確率的なプロセスは、自然で流暢な文章を生成するうえで有効ですが、同時にハルシネーションの温床にもなります。モデルが正確な情報を知らない状態でも、文章の流れとしてそれらしい単語・フレーズを選び続けることで、一見正確に見える誤情報が生成されます。
また、過学習(特定のデータパターンに過度に適合してしまう状態)や、モデルのアーキテクチャ上の欠陥も、ハルシネーションの発生に影響します。これらはモデルの開発・学習段階での問題であり、ユーザー側での対策には限界があります。
ハルシネーションが引き起こすリスク・影響
ハルシネーションは、単なる技術的な誤りにとどまらず、ビジネス・社会・個人に深刻な影響をもたらします。「なんとなく怖い」という漠然とした不安を、「具体的に何が起きるか」に変換して理解することが、適切な対策を講じるための第一歩です。
誤情報の拡散・社会的影響
ハルシネーションによって生成された誤情報が、SNSや報道を通じて拡散するリスクは、社会全体の情報信頼性を低下させる深刻な問題です。生成AIが出力した誤情報を確認せずにSNSに投稿したり、メディアが報道したりすることで、誤情報が急速に広まる可能性があります。
また、悪意のある第三者がハルシネーションを意図的に利用し、フェイクニュースや偽情報を大量生成するリスクも指摘されています。生成AIの普及により、誰でも大量のコンテンツを低コストで生成できるようになった現在、ハルシネーションを悪用した情報操作への対策は社会的な課題となっています。
ビジネスへの影響(意思決定ミス・法的リスク)
企業の業務において、ハルシネーションによる誤情報が意思決定の根拠として使われるリスクは特に深刻です。市場調査・競合分析・法規制の確認など、経営判断に直結する業務で生成AIを活用する場合、誤情報に基づく判断が直接的な損失につながる可能性があります。
さらに、生成AIのハルシネーションによる誤情報の拡散は、名誉毀損・著作権侵害・虚偽情報の流布といった法的リスクに直結します。特に、生成AIの出力をそのまま社外に公開・配信した場合、企業が法的責任を問われる可能性があります。
金融庁が2026年3月3日に公表した「AIディスカッションペーパー(第1.1版)」でも、ハルシネーションのリスクが明示されており、金融機関における生成AIのガバナンス体制整備の重要性が指摘されています。
出典:金融庁「AIディスカッションペーパー(第1.1版)」(2026年3月)
情報セキュリティへの脅威
ハルシネーションは、情報セキュリティの観点からも無視できないリスクをもたらします。悪意のある第三者がハルシネーションを悪用し、フィッシングメールやソーシャルエンジニアリング攻撃に使用するリスクがあります。また、生成AIが機密情報を誤って生成・漏洩するリスクも指摘されています。
特に、RAGを活用して社内データベースと連携した生成AIシステムでは、間接プロンプトインジェクション(悪意のある指示を外部データに埋め込み、AIを誤動作させる攻撃)によるリスクも存在します。経済産業省・総務省の「AI事業者ガイドライン(第1.1版)別添」(2025年3月)でも、RAGの悪用リスクとして明記されています。
ハルシネーションの具体的な事例
ハルシネーションが引き起こした実際の事例を紹介します。これらの事例は、ハルシネーションが「他人事ではない」リスクであることを示しています。事例ごとに「何が起きたか」「なぜ起きたか」「どう防げたか」の3点で解説します。
弁護士が存在しない判例を引用した事例
2023年、米国ニューヨーク州の弁護士スティーブン・シュワルツ氏とピーター・ロドゥカ氏が、審理中の民事訴訟の資料作成にChatGPTを使用した結果、ChatGPTが生成した8件の完全に架空の判例を法廷文書に引用し、裁判所に提出しました。裁判官が判例を確認しようとしたところ実在しないことが発覚し、両弁護士は最終的に合計5,000ドルの制裁金を科せられました。
なぜ起きたか:ChatGPTが「それらしい判例名・裁判所名・判決内容」を確率的に生成したため。弁護士は出力内容を検証せずにそのまま使用しました。
どう防げたか:生成AIの出力を使用する前に、必ず一次情報源(公式の判例データベース等)で内容を確認するファクトチェックの習慣があれば防げた事例です。
AIが実在の人物に関する誤情報を生成した事例
2023年6月、米ジョージア州のラジオ番組司会者マーク・ウォルターズ氏が、OpenAIを名誉毀損で提訴しました。ChatGPTが、ウォルターズ氏を「銃擁護団体セカンド・アメンドメント財団から資金を横領・詐欺した疑いがある人物」とする架空の告訴状の概要を生成・回答したことが原因です。実際にはウォルターズ氏は当該訴訟に一切関与しておらず、ChatGPTが実在の人物と架空の訴訟内容を組み合わせて誤情報を生成したものでした。OpenAIがハルシネーション絡みで名誉毀損を訴えられた初めての事例として注目されました。
また、2024年8月、ノルウェーの男性アルヴェ・ヒャルマル・ホルメン氏が、ChatGPTが「2人の息子を殺害し、21年の禁錮刑を受けた」という虚偽情報を生成していたことを発見。2025年3月、デジタル権利団体Noybがノルウェーのデータ保護当局に苦情を申し立て、OpenAIへの罰金を要求しました。
これらの事例は、生成AIのハルシネーションが実在の人物の社会的評価を著しく傷つけ、法的紛争に発展しうることを示しています。
医療・金融分野での誤回答事例
医療や金融など、情報の正確性が直接的な損害に結びつく高リスク領域でも、ハルシネーションによる誤回答のリスクが指摘されています。
医療分野では、生成AIが薬の用量・副作用・治療法について誤った情報を回答するリスクがあります。厚生労働省の研究でも、「AIによる誤認(ハルシネーション)リスクに注意しつつ、負担軽減と副作用報告の効率化が期待される」と明記されており、専門家監修なしに医療情報に生成AIを活用することの危険性が指摘されています。
金融分野では、日本銀行の資料でも「機密の流出、ハルシネーションを含む回答」が生成AI導入における課題として挙げられており、顧客への情報提供や融資審査など、正確性が求められる業務での活用には特に慎重な対応が求められます。
ハルシネーションの対策方法
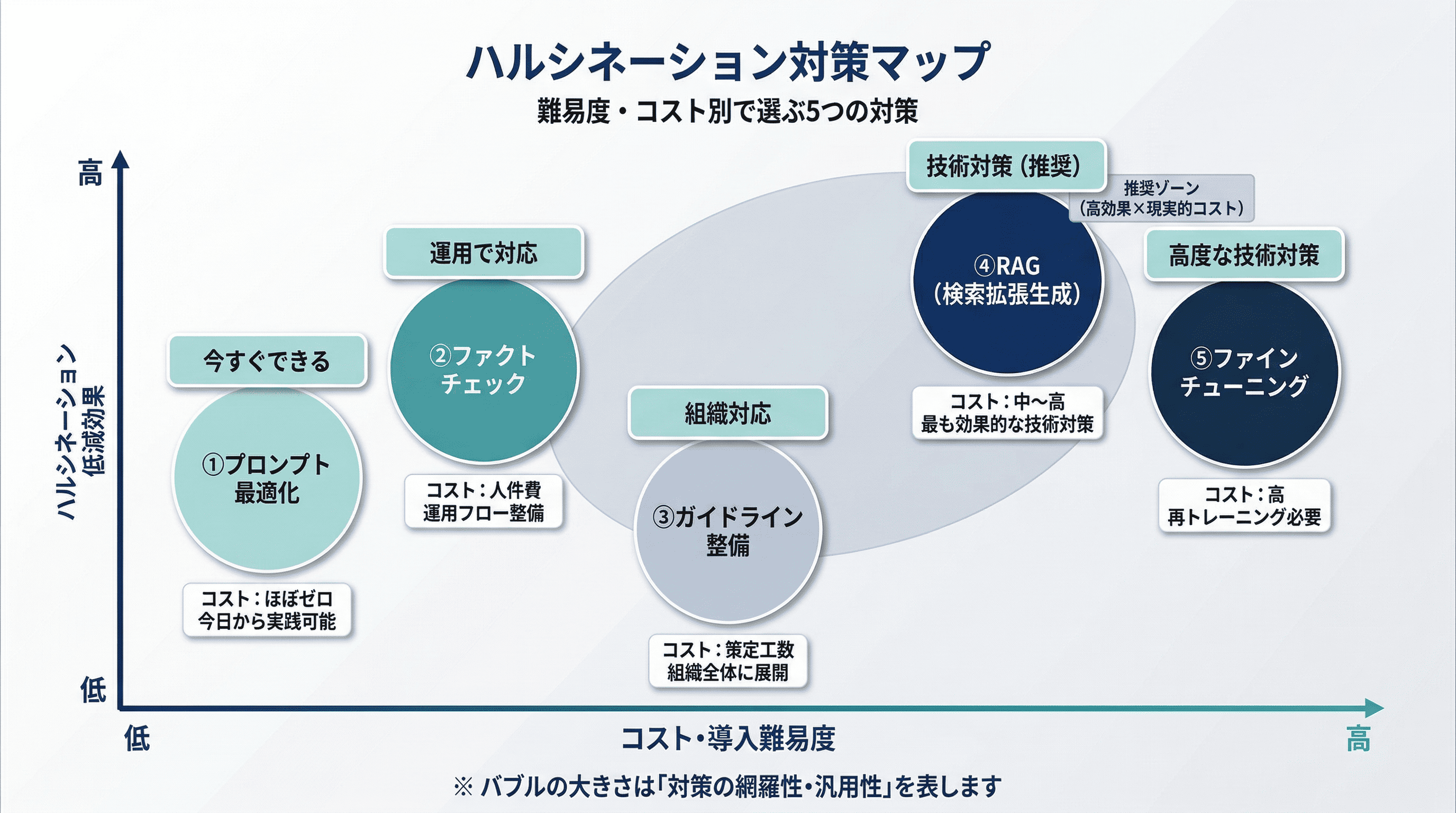
ハルシネーション対策は、ゼロにすることを目指すのではなく、許容範囲内にコントロールすることが現実的なアプローチです。経済産業省・総務省のガイドラインでも、リスクベースアプローチに基づき、事業内容に応じた対策の優先順位付けが推奨されています。以下では、今日からできる運用的対策と、技術的対策を難易度別に解説します。
プロンプトを明確・具体的にする
ハルシネーション対策として最もコストがかからず、今日から実践できる方法が、プロンプトを明確・具体的に設計することです。曖昧な質問を避け、具体的な条件・制約・情報源を指定することで、モデルの推測の余地を減らし、ハルシネーションの発生リスクを低減できます。
具体的には、以下のような工夫が有効です。
- 回答の根拠となる情報源を指定する(「以下の資料のみを参照して回答してください」)
- 不確かな場合は「わかりません」と回答するよう明示的に指示する(「情報がない場合は『わかりません』と答えてください」)
- 回答形式・文字数・対象読者を具体的に指定し、モデルの推測の余地を減らす
- 複雑な質問は複数のステップに分割して問い合わせる
プロンプトの設計次第で、同じモデルでも出力の精度は大きく変わります。生成AIを業務に導入する際は、用途ごとに最適なプロンプトテンプレートを整備し、組織全体で共有することが効果的です。
ファクトチェックを徹底する
技術的な対策と並行して、生成AIの出力を人間が確認・検証するファクトチェック体制を構築することが、ハルシネーション対策の根幹となります。特に、社外に公開する情報・意思決定の根拠となる情報・法的・医療的な内容を含む情報については、必ず専門知識を持つ担当者が一次情報源と照合する運用フローを設けることが求められます。
ファクトチェックを徹底するための具体的な方法として、以下が挙げられます。
- 政府統計・公式文書・学術論文など、信頼性の高い一次情報源で内容を確認する習慣を組織全体に定着させる
- 「AI出力→自動検証→人間レビュー→修正・承認」というフローを整備する
- ハルシネーション発生率・ファクトチェック修正率などのKPIを設定して継続的に改善する
- ファクトチェックツール(専用の検証サービス等)を活用する
- プロンプトに自己検証の項目を入れる、ファクトチェック用のプロンプトを作ってAI自体に検証させる
誤情報を記載しないように、AIでの出力の際に自己検証をさせることでハルシネーションリスクを低減できます。しかし、それでも完璧に防げるわけではないので、必ずダブルチェックの体制を整えることが重要です。
RAG(検索拡張生成)を活用する
RAG(Retrieval-Augmented Generation:検索拡張生成)は、現時点でハルシネーション対策として最も効果的な技術的手法のひとつです。RAGは、LLMによる文章生成に外部情報の検索を組み合わせる仕組みで、モデルが回答を生成する際に、社内データベースや信頼性の高い情報源から関連情報を取得し、その情報に基づいて回答を生成します。
経済産業省・総務省の「AI事業者ガイドライン(第1.1版)別添」(2025年3月)では、RAGについて「LLMによる言語生成に外部情報の検索を組み合わせることによるハルシネーションの抑制」「参照する情報源を指定した検索や出力文における参照元の明示等が可能となることによる出力過程・根拠の透明性向上」が期待されると明記されています。また、通常のファインチューニングと異なり、モデルの再トレーニングを行うことなく参照するデータソースを追加できるため、コスト面でも優れています。
出典:経済産業省・総務省「AI事業者ガイドライン(第1.1版)別添」(2025年3月)
独自の高性能RAG搭載のAIエージェントなら「JAPAN AI AGENT」
「JAPAN AI AGENT」では、業務をヒアリングし特定のタスクを自律的に実行するAI社員をノーコードで作成できます。その結果、毎日の業務プロセスを効率化することが可能です。さらに、上場基準の情報保護とプライバシーマーク取得など、厳格なセキュリティ体制を実現しているため、安心して利用できます。
様々な業務を自律的に遂行するAIエージェント「JAPAN AI AGENT」
日本企業のための
最も実用的なAIエージェントへ!
AIが企業の様々な職種の
方々が
普段行っている
タスクを自律的に実行
JAPAN AI AGENT
実用性の高いAIエージェンを提供
無料の伴走サポート
高いカスタマイズ性
目標設定をだけで自律的にAIが各タスクを実行
グラウンディング・ファインチューニングを行う
RAGと並んで有効な技術的対策として、グラウンディングとファインチューニングがあります。
グラウンディングとは、AIの回答を特定の事実・文書・データソースに基づかせる手法です。モデルが回答を生成する際に、指定した情報源の範囲内でのみ回答するよう制約をかけることで、学習データに存在しない情報を「創作」するリスクを低減できます。
ファインチューニング(fine-tuning:追加学習)は、汎用的なLLMに対して、特定の業務データや専門知識を追加学習させることで、その分野における回答精度を高める手法です。また、RLHF(Reinforcement Learning from Human Feedback:人間のフィードバックによる強化学習)を活用することで、人間の評価に基づいてモデルの出力品質を継続的に改善することも可能です。ただし、ファインチューニングはモデルの再トレーニングが必要なため、RAGと比較してコストと時間がかかります。用途・コスト・精度要件を総合的に判断したうえで、RAGとの使い分けを検討することが推奨されます。
ガイドライン・マニュアルを整備する
技術的な対策と同様に重要なのが、組織としてのAI利用ルールの策定です。生成AIのハルシネーション問題への対応は、技術的な課題であると同時に、組織全体のガバナンス・リスク管理の問題でもあります。
組織として整備すべき基本的なガイドライン・マニュアルの例として、以下が挙げられます。
- 「AIの回答は必ず一次情報源で確認する」というルールの明文化
- 「機密情報・個人情報を生成AIに入力しない」という情報管理ルールの策定
- 生成AIの利用が許可される業務・禁止される業務の明確化
- ハルシネーションが発生した場合の報告・対応フローの整備
- AIガバナンス体制の構築と定期的な見直し
経済産業省・総務省のガイドラインでは、リスクベースアプローチに基づき、事業内容に応じた対策の優先順位付けが推奨されています。自社の業務内容・リスク許容度に応じて、適切なガイドラインを整備することが重要です。
ハルシネーションに関してよくある質問
Q. ハルシネーションはなくなりますか?今後の見通しは?
現時点では、ハルシネーションを完全になくすことは技術的に困難です。LLMの確率的な文章生成プロセスに起因するため、モデルの構造的な特性として残り続けます。ただし、モデルの改善・RAGの活用・グラウンディング等の技術進化により、発生頻度は減少傾向にあります。「ハルシネーションが起きる前提で使う」という姿勢を持ち、適切な確認体制を整えることが重要です。
Q. ChatGPTやGeminiでもハルシネーションは起きますか?
はい、ChatGPT・Gemini・Claudeをはじめ、すべての生成AIでハルシネーションは起こりえます。ただし、モデルによって発生頻度や傾向は異なります。最新モデルほど改善されていますが、ゼロではないため、重要な情報については必ず一次情報源で確認することが必要です。特定のモデルが「ハルシネーションを起こさない」という前提で使用することは避けてください。
Q. ハルシネーションを完全に防ぐ方法はありますか?
現時点では、ハルシネーションを完全に防ぐ方法はありません。しかし、プロンプトの改善・ファクトチェックの徹底・RAGの活用を組み合わせることで、発生リスクを大幅に低減することは可能です。最も重要なのは、重要な判断には必ず人間の確認を挟むことです。生成AIはあくまでも「補助ツール」として位置づけ、最終的な判断は人間が行う体制を維持することが、ハルシネーションリスクを管理するうえで最も根本的な対策となります。
高性能RAGによりハルシネーションを低減するなら、「JAPAN AI」
ハルシネーションとは、AIが事実に基づかない情報をもっともらしく出力する現象で、大規模言語モデルの確率的な文章生成プロセスに起因するものだという事を解説しました。本記事で解説したハルシネーションに関する要点を整理します。
- 種類は「内在的ハルシネーション(学習データとの矛盾)」と「外在的ハルシネーション(存在しない情報の創作)」の2種類に大別される
- 発生原因は「学習データの偏り・不足」「プロンプトの曖昧さ」「AIモデルの構造的限界」の3軸で整理できる
- リスクは誤情報の拡散・意思決定ミス・名誉毀損訴訟・情報セキュリティ脅威など多岐にわたる
- 対策は「プロンプトの明確化」「ファクトチェックの徹底」「RAGの活用」「グラウンディング・ファインチューニング」「ガイドラインの整備」の組み合わせが有効
- ハルシネーションは完全にゼロにはできないが、許容範囲内にコントロールすることは可能
- 生成AIはあくまでも「補助ツール」として位置づけ、最終的な判断は人間が行う体制を維持することが最重要
生成AIのハルシネーション問題への対応は、技術的な課題であると同時に、組織全体のガバナンス・リスク管理の問題でもあります。ハルシネーションを正しく理解したうえで生成AIを活用することが、安全で効果的なAI活用の第一歩です。
ハルシネーションを低減するためにRAGの活用だと解説しましたが、「JAPAN AI」では自社独自の高性能RAGを搭載したAIエージェントを提供しています。企業・ビジネスでのAI活用にお悩みの方、ハルシネーションやセキュリティを気にされている方、学習されたくないデータがあってAIを活用できないと思っている方は、ぜひ資料をダウンロードしてみてください。
様々な業務を自律的に遂行するAIエージェント「JAPAN AI AGENT」
日本企業のための
最も実用的なAIエージェントへ!
AIが企業の様々な職種の
方々が
普段行っている
タスクを自律的に実行
JAPAN AI AGENT
実用性の高いAIエージェンを提供
無料の伴走サポート
高いカスタマイズ性
目標設定をだけで自律的にAIが各タスクを実行
この記事をシェアする



AIを活用した業務工数の削減 個社向けの開発対応が可能
事業に沿った自社専用AIを搭載できる「JAPAN AI CHAT」で業務効率化!
資料では「JAPAN AI CHAT」の特徴や他にはない機能をご紹介しています。具体的なAIの活用事例や各種業務での利用シーンなどもまとめて掲載。
あわせて読みたい記事








